If you were to ask any developer which document format is the most preferred right now, the answer would unequivocally be Markdown. Currently, Markdown is being used with GitHub, GitLab, Bitbucket, and more as a default document format for most of the services including issue tracking. Furthermore, it is also integrated with almost all text editors like IntelliJ, VSCode, Vim, and Emacs, and plugins can be used to utilize syntax highlighting and preview features.
TOAST UI Editor takes this one step further and provides an editor interface that integrates WYSIWYG (What You See is What You Get) with Markdown. WYSIWYG editor allow you to view complex formattings like tables intuitively, and it can also be an effective tool to use when collaborating among developers and non-developers, as the WYSWYG editor can be used by non-developers who may not be as familiar with Markdown. Upon such merits, the TOAST UI Editor has been consistently collecting users for the past couple of years, and last month, it reached a significant milestone of getting 10k GitHub stars.
TOAST UI Editor is constantly trying to provide better user experience while maintaining the core identity as a Markdown editor. With the recent release of v2.0, TOAST UI Editor has replaced the original Markdown parser, markdown-it, with a brand new Markdown parser built on commonmark.js. It is expected that the new Markdown parser is not only a solution to many problems that v1.x faced, but also is a key steppingstone for more and bigger improvements in the future.
This article studies the shortcomings and limitations the previous Markdown editors including TOAST UI Editor have and will also discuss how the new Markdown parser implemented in v2.0 can help address said issues. Lastly, we will close with speculating about how this new parser can improve the utility of Markdown.
Markdown Editor’s Features and Problems
While TOAST UI Editor offers both Markdown editor and the WYSIWYG editor, the Markdown editor alone can stand out among other editors in terms of utility. Syntax highlighting, live preview, and toolbar button are all examples of must-have features for a Markdown editor. However, numerous editors, including TOAST UI Editor, do not perfectly offer such features due to technical difficulties. In this section, we will discuss each feature along with related issues and causes in detail.
Syntax Highlighting
The first feature that comes to mind when editing Markdown documents is the syntax highlighting. As many developers must already know, syntax highlighting analyzes the Markdown document to emphasize any syntax with significance visually through styling. On editors that offer syntax highlighting, you can view that the Markdown has been applied on the current document without having to preview the rendered product. On the other hand, in environments like GitHub’s issue registration form, where syntax highlighting is not supported, it is important to use the preview feature abundantly as you write.
However, almost no editor supports Markdown’s syntax highlighting feature perfectly. This is because different editors use different syntax highlighting modules, so the original Markdown parser cannot be used. Therefore, because different editors have to perform syntax analysis differently, it is not easy to produce the identical results with the parser that is used for the actual rendering.
For example, TOAST UI Editor uses the markdown-it for the HTML conversion, but for syntax highlighting, the CodeMirror’s GFM mode is used. The CodeMirror’s mode systems use an implementation of a tokenizer for different languages for syntax analysis, but it cannot be as accurate as analyzed using markdown-it because it is not a full parser. Therefore, as the image below demonstrates, it is common for the highlighted syntax to appear different compared to the live preview.

As for the VSCode’s markdown plugin, it also uses markdown-it for the HTML conversion, yet it uses a TextMate grammar, which is common in many other editors, for syntax analysis. Upon glancing at the image below, it is clear to see that a problem that is different from that occurred with CodeMirror occur.
The other piece of issue is the performance. Since editors have to perform a syntax analysis over the entire document every time the text is changed, as the size of the document grows, so grows the editing time. CodeMirror’s mode system implements an internal optimization to prevent this from happening, so it is not as noticeable. However, with editors like VSCode that rely on the TextMate grammar, it is clear to see that editing a large Markdown document will slow down the entire process due to syntax highlighting.
Live Preview
While simply having syntax highlighting can be a great help, it cannot fully predict what the converted Markdown document will look like. Especially when it comes to elements like images and tables, it is difficult to accurately predict how the document will look without visually verifying the rendered results. The live preview minimizes the unnecessary risks by displaying the rendered document before having to save. TOAST UI Editor, especially, provides a split-screen preview and the editor to allow you to verify your work as you go. If you’re someone who has written a lengthy issue registration on GitHub while constantly having to command-tab between the preview and the editor, you will already have great appreciation for this feature.
However, the live preview feature, much like the syntax highlighting feature, is not exempted from the performance issues. Since the editor has to convert the entire document to create the HTML every time the text is edited, the larger files will inevitably slow down the editing process. Furthermore, as external resources like images have be to rerendered, it can cause blinking on the preview screen. If you are running a script with an extended grammar through a plugin, the script has to be executed every time and can interrupt the process.
In order to address the issue, TOAST UI Editor has implemented a debounce method to update the render only when there have been no changes within a given timeframe, but this method slows down the preview’s reaction, thereby reducing the utility. Furthermore, this method still cannot fully address the unnecessary rendering problem nor the script reexecution problem. The animation below is an example of the delayed preview update in TOAST UI Editor and the reexecution of the chart plugin.
Other possible solution is comparing the original DOM tree with the newly rendered DOM tree to partially update the changed, but this method calls for additional processing for DOM tree comparisons and can may lead to another performance issue.
Using Toolbars to Change Document Structure
Because Markdown is a markup language designed for document editing, it is often required to apply styles selectively to an area. Therefore, some Markdown editors like TOAST UI Editor, offer a toolbar composed of style changes like bold, italic, and lists, and new structures like link, image, and tables for the users’ convenience. However, implementing a toolbar in a Markdown editor can be tricky, as it has to satisfy the two features.
First, button’s state needs to be synced according to the editor’s cursor location and its selected area. For example, if the cursor is located within a list, a list button has to be activated, and if the cursor is located within a bolded text, the bold button must be activated. Such feature should be familiar if you have used editors like Google Docs or MS Word.
However, it is not an easy task to verify whether a certain grammar has been applied to the text at a selected area. This process requires a separate syntax analysis, and it has to analyze the nearby lines as well as the cursor’s location, as per the nature of Markdown grammar. CodeMirror’s mode system can provide information from the analysis done for syntax highlighting, but as I have mentioned earlier, the parser for syntax highlighting is not perfect. Therefore, the information available to us is also limited.
The next requirement is the feature that applies a styling or inserts an element to the cursor’s location when a button has been clicked. Frankly, inserting images and links at the cursor’s location is not a difficult task. However, managing styling for a textarea that spans over multiple lines is quite complicated, and the same reasoning for the button state synchronization applies.
For example, if the cursor is located on a certain element within a list, clicking the “Ordered List” button should iterate through the nearby lines to determine whether the line is located within the same list and look for the starting sign (- hyphen or * an asterisk) to turn them into numbers and dots. TOAST UI Editor has a separate module to handle such list computation, but although it is code-heavy, it cannot handle a scenario where the element spans over multiple lines yet, like in the image below.
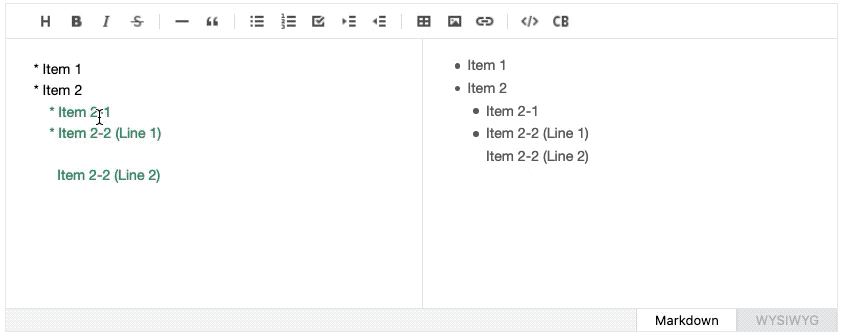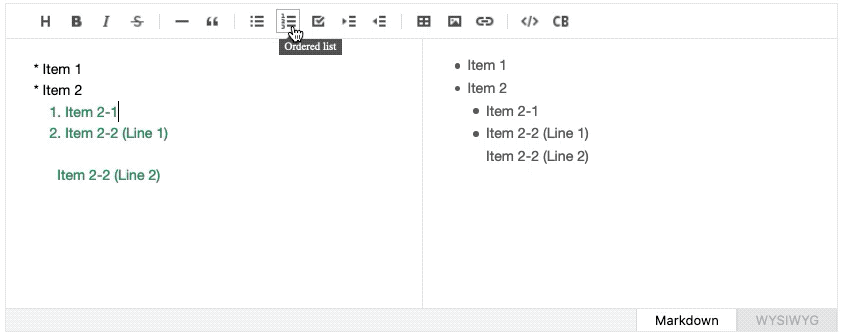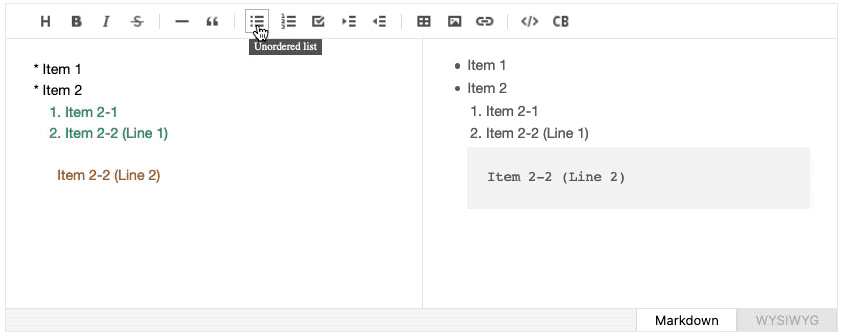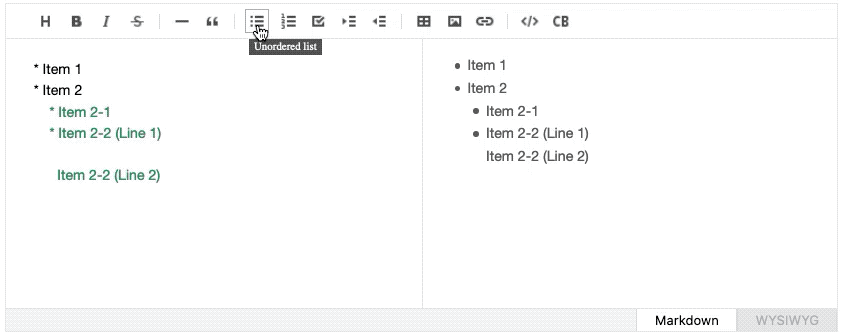
Learning From the Integrated Development Environments (IDE)
If you have made it this far, I’m sure you’re starting to understand the shortcomings of traditional Markdown editors. It all lies in the fragmentation of the Markdown parser. In other words, it is because different modules all perform their own syntax analysis despite the fact that all features like syntax highlighting, HTML conversion, and toolbars require syntax analysis. It may sound obvious, but if a single central parser were to take care of everything, it would lead to a much more accurate and unified utility while making the implementation logic simpler. Then why is this not the case?
The reason lies in the fact that most Markdown parsers have been built with the sole purpose of converting Markdown grammar into HTML. Features like syntax highlighting and structure modification require a mapping information between the source code and the analyzed syntax tree, but popular Markdown parsers like markdown-it do not provide such information. Furthermore, since it has been built to convert the entire Markdown document in one-go, it cannot guarantee the performance when it is expected to modify the content live like an editor.
Then, how can we solve this problem? We did not have to look far for the answer: it was the Integrated Development Environment (IDE).
In actuality, the problems that we face with the Markdown editors is the same as the problems developers face with the text editors, or the IDEs. For example, many editors like VSCode, Sublime Text, Eclipse use regex based TextMate grammar for syntax analysis, but since it cannot fully analyze the true meaning of the syntax, it has remained stagnant at being able to color different keywords. Furthermore, the IDEs need a separate analyzer for features like auto-fill, refactoring, and go-to-definitions, and the support for such differs too, as editors have to implement separate custom language support for different editors.
If you’re someone who is interested in different development environments, you are probably already familiar with the two popular solutions to this problem. They are the Tree Sitter and the Language Server Protocol, henceforth LSP.
Tree Sitter
Tree sitters transcend beyond the traditional regex based syntax analysis, and constructs a syntax tree based on the whole context. It started as an internal module for Atom editor, but it has been implemented in many other editor environments. Because parsers built on tree sitter paradigm are built to be used in editor environments that allow live editing, it has two distinct characterizations. For one, it creates a Concrete Syntax Tree that contains one-to-one mapping information between the source codes. Secondly, it supports incremental parsing.
The concrete syntax tree, unlike the Abstract Syntax Tree, contains all information of all syntax without gaps. Tree sitter’s syntax trees additionally contain the source code’s beginning and ending location for every syntax, so it can decipher what a selection of the source code means. The Tree Sitter Release Notes from Atom editor blog shows how this information can be utilized, and it can be applied to code folding, syntax-aware selection to improve such features.
Incremental parsing refers to the method of only parsing the changed portions of the document to update the syntax tree instead of parsing the entire document every time. Therefore, it keeps a previously created syntax tree and uses the changed text information to update the corresponding part of the original tree. In discussing an editor, where a document to be parsed is constantly changing, it is the most important and optimal aspect of an editor. With this, the tree sitter can parse through a large source code to update the syntax tree without performance loss.
(CodeMirror also contemplates similar issues while preparing for the most recent major update CodeMirror 6, and were inspired by tree sitter to build Lezer, a new parser. The detailed considerations and process is carefully documented in the developer’s blog, so I highly recommend that you take your time to read it if you are interested.)
Language Server Protocol (LSP)
LSP is a set of rules that states the necessary language server’s specs when supporting features like auto-complete and refactoring in IDE. LSP, unlike the traditional IDE’s approach, uses a separate server for available languages on the client (editor) side and communicate through inter-process methods. In other words, simply hosting a language server that adheres to the LSP can allow different editors to use the same IDE features. LSP was first developed by Microsoft for editors like VSCode and it is being used in a wide range of editors like IntelliJ, Emacs, and Vim.
Frankly, the interworkings of a client side’s separate structure and communication between processes are not the core concept when building a Markdown editor for the web. The more important idea lies behind the server, and TypeScript’s ts-server can be used as an example that is familiar to many readers.
TypeScript is mainly composed of tsc and ts-server. The tsc is mainly used for compiling an entire file at once as it can be used for bundling purposes by connecting to webpacks and other tools. On the other hand, ts-server is executed within the editor and updates the result of syntax analysis every time the text is changed, and it also returns results like auto-complete and type errors given the circumstances. If you have developed TypeScript on editors like VSCode and IntelliJ and have admired the TypeScript development tools, now know to thank ts-server for its service.
(ts-server does not yet support LSP, but the LSP wrapper library can be used if you need LSP support.)
Another feature that calls our attention is the refactoring feature. When developing TypeScript, I’m sure most of you have used refactoring features like “Rename Function.” This means that the language server goes further than just parsing the source code and returning information and even directly modifies the source code as well. In other words, the language server changes the syntax analysis tree’s structure, and uses the changed structure to update the source code and to update the changed results. To perform correctly, LSP comes with CodeAction requests defined, and this feature can be useful when addressing the problemns mentioned in “Using Toolbars to Change Document Structure.”
The language server can be held responsible for most of the tasks done by tree sitters, and actually, there are APIs suggested for syntax highlighting in LSPs. However, because language servers are responsible for much more complicated tasks than the tree sitters and because it is difficult to support incremental parsing, it is too heavy and slow for features like live syntax highlighting and code folding. Therefore, it can be said that the tree sitters and LSP have different uses and implementations, and they have a mutually beneficial relationship.
New Markdown Parser: ToastMark
Upon contemplating the aforementioned information, we decided that a new Markdown parser that highlights the strengths of tree sitters and LSPs can help us solve our problems with original editors. However, since building a new Markdown parser is an enormous task, we decided to improve an already well-built opensource, and finally decided on the commonmark.js upon days of debates.
The commonmark.js is a reference implementation of the CommonMark Specs, and it is the only JavaScript library that strictly adheres to the CommonMark Specs. Because it is a reference implementation, it is easy to parse and extend the code, and we also realized that it would be easiest to modify when CommonMark specs change eventually.
After a month of improvement work, ToastMark, a brand new Markdown parser, was born. ToastMark has the following three characterizations.
1. Construction of Abstract Syntax Tree that Holds Source Mapping Information
ToastMark constructs a Markdown document’s abstract syntax tree, and saves the starting position and the ending position of the source code to each node. The saved positions are used in diverse features like syntax highlighting, toolbar button synchronization, and scroll sync with live preview. The reason we chose the abstract syntax tree unlike the tree sitter is that this parser is used for more than mere syntax highlighting. For just syntax highlighting, concrete syntax tree is more effective, but when it comes to searching for a certain aspect of a document or changing the structure of a document, abstract syntax trees are much more effective. Furthermore, the token structure that composes different elements of the Markdown is simple enough that it can be implemented using an abstract syntax tree just by adding a few pieces of information.
Because commonmark.js already had an API that returned abstract syntax tree information as well as the positional information of the block element, we were able to add source code’s positional information about an inline element without much trouble.
2. Incremental Parsing With Respect to Changes in Documents
ToastMark supports incremental parsing like tree sitters. Thus, it keeps a previously parsed syntax tree, and only update if necessary with respect to changes in documents. If there is a change in the editor, it sends the source code’s positional and textual information to ToastMark, and ToastMark updates the parts of the syntax tree to return the changed node’s information. Let’s look at how to use it.
const toastMark = new ToastMark('# Hello World');
// Changing the first character # to a -
const result = toastMark.editMarkdown([1, 1], [1, 2], '-');
const { removedNodeRange, newNodes } = result;
// Update Markdown editor's syntax highlighting
refreshSyntaxHighlighting(newNodes);
// Update the preview DOM
refreshPreview(removedNodeRange, newNodes);The changed node’s information is used to update the syntax highlighting style and the live preview DOM. Because it returns the deleted node’s id as well as the newly added array of nodes, it can accurately update only what is changed. With the help of this feature, users can work on large Markdown documents without performance loss and with improved utility due to updatable syntax highlighting and live preview.
3. Searching and Changing the Syntax Tree
In order to sync the toolbar button’s state, we need to know where the cursor location is with respect to its source code’s position and which Markdown element it matches with every time it is changed. For this, we need to know the node’s location with respect to the location even if there were no changes in the document. Also, in order to use the node information that matches the preview’s DOM, we must assign each node an id, and we must be able to call nodes through these ids. For this purpose, ToastMark offers the following methods.
// Returns the first node at line 3
toastMark.findFirstNodeAtLine(3);
// Returns the node that matches the fifth element of the 2nd line
toastMark.findNodeAtPosition([2, 5]);
// Returns the node with id of 10
toastMark.findNodeById(10);When the toolbar button is clicked, it must change the structure of the document. Changing the paragraph into a list and changing unordered list into ordered list are such examples. This process encompasses changing the syntax tree and generating and returning the actual Markdown source code. While it is not yet implemented in the current version, we plan on adding more APIs related to this feature in the following updates.
Improvements in TOAST UI Editor 2.0
TOAST UI Editor 2.0 does not have a major newly added feature as the main focus of the update was to stabilize the Markdown parser and change the structure of the modules and bundles. However, the mere fact that we changed the parser to ToastMark has drastically improved the accuracy and stability of the Markdown editor compared to previous versions.
Improved Syntax Highlighting in TOAST UI Editor
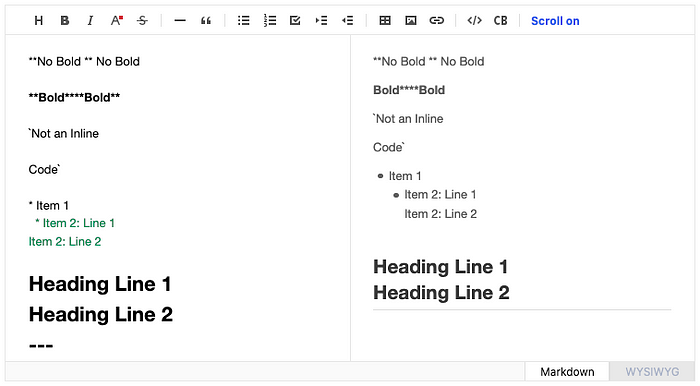
We removed all previously used CodeMirror Markdown, and changed to a method where we use the CodeMirror API to directly style a selected syntax. Now, since preview and syntax highlighting features all rely on the ToastMark’s syntax tree, you can see that the two results are perfectly identical in the following image.
Improved Live Preview in TOAST UI Editor
As we mentioned earlier, the live preview feature parses the entire document and updates the entire DOM. In order to optimize the performance, we made it so that it updates only when the input has stopped for a given time, and we also had the problem that extensible plugins refreshed every time it happened. However, from v2.0, with the implementation of ToastMark’s incremental parsing, it only parses and updates what has been changed, so the preview can be displayed without delays and without unnecessary reexecution of plugins in “realtime”.
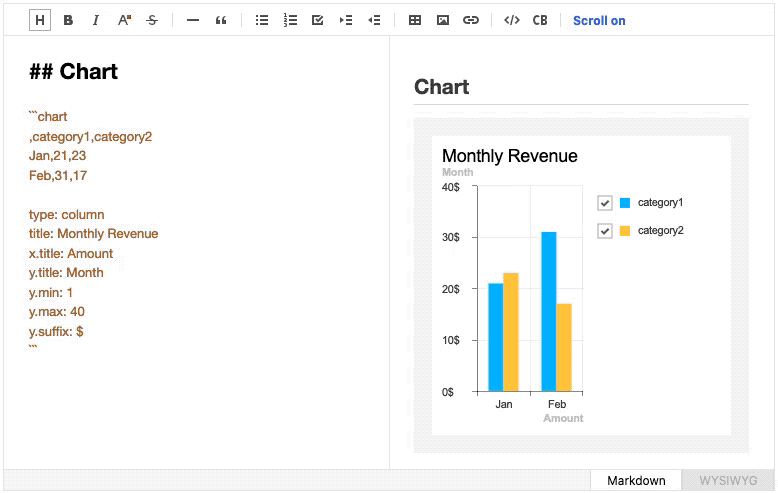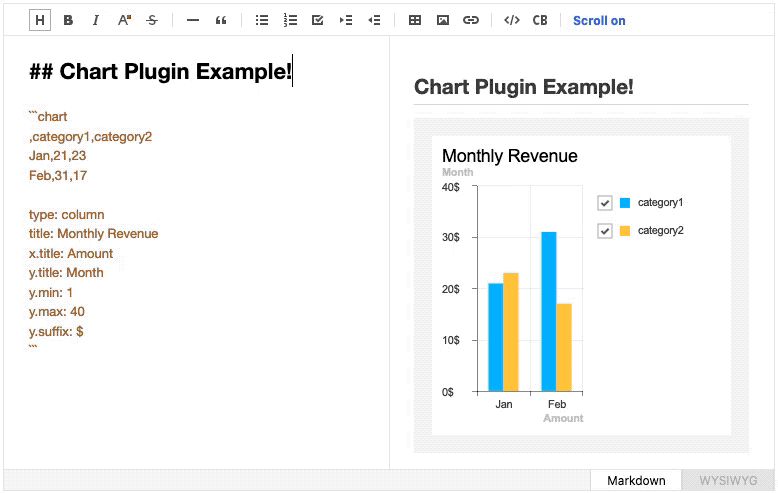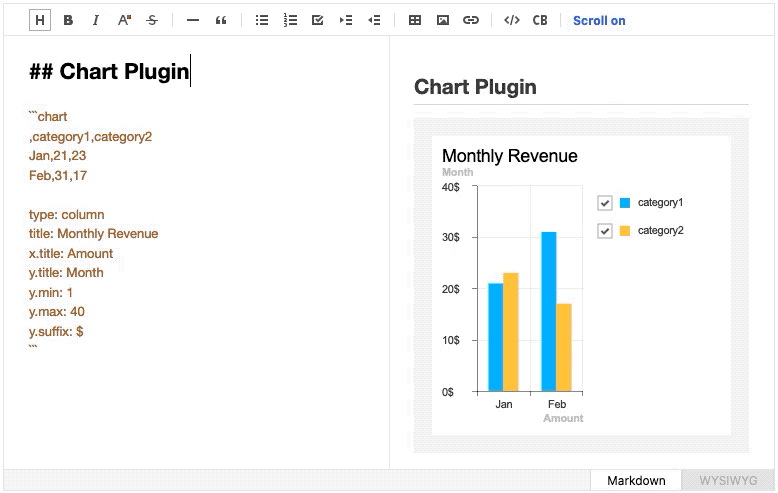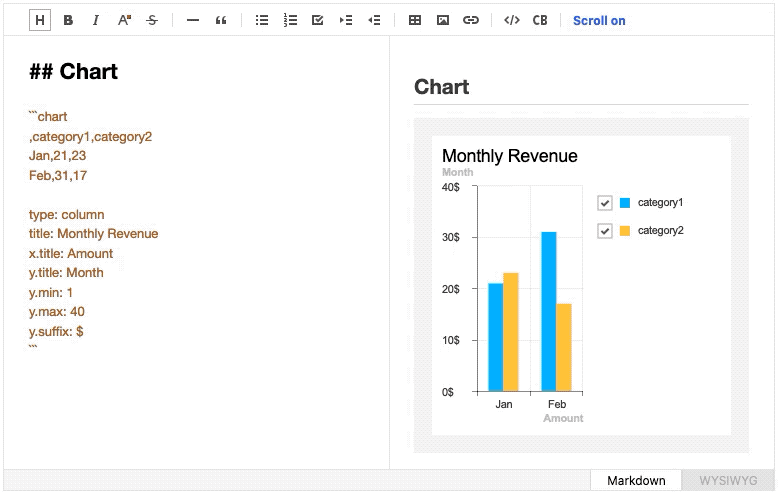
Furthermore the feature that allows a live synchronization of Markdown editor and the live preview’s scroll location has also improved with the help of detailed mapping information provided by ToastMark.
Improved Toolbar Button Status With Respect to the Cursor Location
The synchronization of toolbar button status is an issue that has required constant improvements for a while. In the original version, it performed well with bold, italic, line-through, and other features, but when it came to elements like lists and tables, it suffered. While we could use the information provided by CodeMirror’s Markdown mode tokenizer, the information itself was incomplete, so we needed to perform additional computation for better synchronization.
However, with ToastMark, we are able to receive exact location of the cursor and its corresponding Markdown node information, so we were able to make huge improvements with little code.
What to Look For in v2.X
There are still many more aspects that we could improve using ToastMark. Frankly, we could have implemented it earlier, but we were putting it off as it required separate syntax analysis. Now, because we have access to exact syntax analysis data, we can implement many more features easily. Therefore, on minor updates after 2.0, we plan on trying different things with the ToastMark and trying to improve the Markdown editor and the preview utility.
The most urgent task is improving the utility of the toolbar button. Right now, we are satisfied improving the synchronization between the cursor location and the button status, but for better usability, we need to make more improvements like disabling a state of a button given a selected area. Furthermore, we can improve it even more by making the editor consider not only the state of the cursor but also the state of the selected area when clicked, and we can remove the existing logic responsible for syntax analysis to make the code simpler.
We are still looking to add more features like sectional code folding, code formatting, adding table columns/rows, and highlighting changed area in preview. While these are mere possibilities as of this moment, we plan on adding them upon consideration of utility and priority later. If you have more features that you would like to see, feel free to leave us an issue.
Future of ToastMark
As ToastMark has only taken its first step, there are numerous possible improvements left to be made. Furthermore, because it is a library that is used only in TOAST UI Editor, we did not register it as a separate npm package, and the API will continue to change with respect to the needs of the editor. In other words, it is not yet suitable for outside use.
However, ToastMark will continue to grow with TOAST UI Editor, and once it has achieved appropriate stability, we plan on releasing it to the public officially. We have enumerated some of ToastMark’s characteristics and APIs on GitHub repository, so feel free to check it out if you are interested, and if you have some good ideas, please leave us an issue on Github.
The Future of TOAST UI Editor
So far, we have discussed the new Markdown parser, ToastMark, why it came to be, and what we improved using it. ToastMark has played a major role in improving the Markdown editor’s utility and it has potential to lead more changes in the future. However, the ToastMark’s role is still not finished. ToastMark is an important starting point toward true integration between the Markdown editor and the WYSIWYG editor.
Currently, the Markdown editor is structured in a mutual beneficial system where the CodeMirror and ToastMark manage text information and changed information in sync. The next step is making ToastMark solely responsible for text information and making the editor be simply responsible for cursor’s movements and event handling. Like the Redux-React relationship, ToastMark can be a state manager, and the editor can simply serve as the view. Then, we can have a Markdown editor that is not reliant on CodeMirror and that is more centralized.
Taking even more steps forward, we can apply the same structure to the WYSIWYG editor. In other words, ToastMark can be a single state manager, and both the Markdown editor and the WYSIWYG editor can take on the role of views. If this becomes possible, we can remove the Squire dependency that we use to implement WYSIWYG editor, and eventually have a lighter WYSIWYG editor.
For example, in the original structure, the WYSIWYG editor would edit the HTML (DOM), and the Markdown editor would edit the Markdown, so every time there has to be a conversion between the two editors, the entire document had to be converted from Markdown to HTML and from HTML to Markdown. This process caused changes in data that were not intentional. However, with the new structure, because two editors rely on the single AST managed by the ToastMark, we can get rid of the unnecessary conversion between editors and the problems that follow.
Of course, there are still a lot of technical hurdles for us to jump through, so it requires us to explore and prototype diligently. More details will be discussed in future articles. Right now, instead of looking far ahead in the future, focus on the newly released v2.0, and I hope that you can enjoy the Markdown editor’s utility that will be constantly updated and improved.
